![]()
[Nov-2024] Verified Google Professional-Machine-Learning-Engineer Bundle Real Exam Dumps PDF
Professional-Machine-Learning-Engineer Dumps PDF New [2024] Ultimate Study Guide
NEW QUESTION # 135
You are the Director of Data Science at a large company, and your Data Science team has recently begun using the Kubeflow Pipelines SDK to orchestrate their training pipelines. Your team is struggling to integrate their custom Python code into the Kubeflow Pipelines SDK. How should you instruct them to proceed in order to quickly integrate their code with the Kubeflow Pipelines SDK?
- A. Use the predefined components available in the Kubeflow Pipelines SDK to access Dataproc, and run the custom code there.
- B. Deploy the custom Python code to Cloud Functions, and use Kubeflow Pipelines to trigger the Cloud Function.
- C. Use the func_to_container_op function to create custom components from the Python code.
- D. Package the custom Python code into Docker containers, and use the load_component_from_file function to import the containers into the pipeline.
Answer: C
Explanation:
The easiest way to integrate custom Python code into the Kubeflow Pipelines SDK is to use the func_to_container_op function, which converts a Python function into a pipeline component. This function automatically builds a Docker image that executes the Python function, and returns a factory function that can be used to create kfp.dsl.ContainerOp instances for the pipeline. This option has the following benefits:
* It allows the data science team to reuse their existing Python code without rewriting it or packaging it into containers manually.
* It simplifies the component specification and implementation, as the function signature defines the component interface and the function body defines the component logic.
* It supports various types of inputs and outputs, such as primitive types, files, directories, and dictionaries.
The other options are less optimal for the following reasons:
* Option B: Using the predefined components available in the Kubeflow Pipelines SDK to access Dataproc, and run the custom code there, introduces additional complexity and cost. This option requires creating and managing Dataproc clusters, which are ephemeral and scalable clusters of Compute Engine instances that run Apache Spark and Apache Hadoop. Moreover, this option requires writing the custom code in PySpark or Hadoop MapReduce, which may not be compatible with the existing Python code.
* Option C: Packaging the custom Python code into Docker containers, and using the load_component_from_file function to import the containers into the pipeline, introduces additional steps and overhead. This option requires creating and maintaining Dockerfiles, building and pushing Docker images, and writing component specifications in YAML files. Moreover, this option requires managing the dependencies and versions of the Python code and the Docker images.
* Option D: Deploying the custom Python code to Cloud Functions, and using Kubeflow Pipelines to trigger the Cloud Function, introduces additional latency and limitations. This option requires creating and deploying Cloud Functions, which are serverless functions that execute in response to events.
Moreover, this option requires invoking the Cloud Functions from the Kubeflow Pipelines using HTTP requests, which can incur network overhead and latency. Additionally, this option is subject to the quotas and limits of Cloud Functions, such as the maximum execution time and memory usage.
References:
* Building Python function-based components | Kubeflow
* Building Python Function-based Components | Kubeflow
NEW QUESTION # 136
You are an ML engineer at a global car manufacturer. You need to build an ML model to predict car sales in different cities around the world. Which features or feature crosses should you use to train city-specific relationships between car type and number of sales?
- A. One feature obtained as an element-wise product between binned latitude, binned longitude, and one-hot encoded car type
- B. One feature obtained as an element-wise product between latitude, longitude, and car type
- C. Three individual features binned latitude, binned longitude, and one-hot encoded car type
- D. Two feature crosses as a element-wise product the first between binned latitude and one-hot encoded car type, and the second between binned longitude and one-hot encoded car type
Answer: C
NEW QUESTION # 137
While performing exploratory data analysis on a dataset, you find that an important categorical feature has 5% null values. You want to minimize the bias that could result from the missing values. How should you handle the missing values?
- A. Replace the missing values with a placeholder category indicating a missing value.
- B. Remove the rows with missing values, and upsample your dataset by 5%.
- C. Move the rows with missing values to your validation dataset.
- D. Replace the missing values with the feature's mean.
Answer: A
Explanation:
The best option for handling missing values in a categorical feature is to replace them with a placeholder category indicating a missing value. This is a type of imputation, which is a method of estimating the missing values based on the observed data. Imputing the missing values with a placeholder category preserves the information that the data is missing, and avoids introducing bias or distortion in the feature distribution. It also allows the machine learning model to learn from the missingness pattern, and potentially use it as a predictor for the target variable. The other options are not suitable for handling missing values in a categorical feature, because:
* Removing the rows with missing values and upsampling the dataset by 5% would reduce the size of the dataset and potentially lose important information. It would also introduce sampling bias and overfitting, as the upsampling process would create duplicate or synthetic observations that do not reflect the true population.
* Replacing the missing values with the feature's mean would not make sense for a categorical feature, as
* the mean is a numerical measure that does not capture the mode or frequency of the categories. It would also create a new category that does not exist in the original data, and might confuse the machine learning model.
* Moving the rows with missing values to the validation dataset would compromise the validity and reliability of the model evaluation, as the validation dataset would not be representative of the test or production data. It would also reduce the amount of data available for training the model, and might introduce leakage or inconsistency between the training and validation datasets. References:
* Imputation of missing values
* Effective Strategies to Handle Missing Values in Data Analysis
* How to Handle Missing Values of Categorical Variables?
* Google Cloud launches machine learning engineer certification
* Google Professional Machine Learning Engineer Certification
* Professional ML Engineer Exam Guide
* Preparing for Google Cloud Certification: Machine Learning Engineer Professional Certificate
NEW QUESTION # 138
You work at a subscription-based company. You have trained an ensemble of trees and neural networks to predict customer churn, which is the likelihood that customers will not renew their yearly subscription. The average prediction is a 15% churn rate, but for a particular customer the model predicts that they are 70% likely to churn. The customer has a product usage history of 30%, is located in New York City, and became a customer in 1997. You need to explain the difference between the actual prediction, a 70% churn rate, and the average prediction. You want to use Vertex Explainable AI. What should you do?
- A. Train local surrogate models to explain individual predictions.
- B. Configure integrated gradients explanations on Vertex Explainable AI.
- C. Configure sampled Shapley explanations on Vertex Explainable AI.
- D. Measure the effect of each feature as the weight of the feature multiplied by the feature value.
Answer: C
Explanation:
* Option A is incorrect because training local surrogate models to explain individual predictions is not a feature of Vertex Explainable AI, but rather a general technique for interpreting black-box models. Local surrogate models are simpler models that approximate the behavior of the original model around a specific input1.
* Option B is correct because configuring sampled Shapley explanations on Vertex Explainable AI is a way to explain the difference between the actual prediction and the average prediction for a given
* input. Sampled Shapley explanations are based on the Shapley value, which is a game-theoretic concept that measures how much each feature contributes to the prediction2. Vertex Explainable AI supports sampled Shapley explanations for tabular data, such as customer churn3.
* Option C is incorrect because configuring integrated gradients explanations on Vertex Explainable AI is not suitable for explaining the difference between the actual prediction and the average prediction for a given input. Integrated gradients explanations are based on the idea of computing the gradients of the prediction with respect to the input features along a path from a baseline input to the actual input4. Vertex Explainable AI supports integrated gradients explanations for image and text data, but not for tabular data3.
* Option D is incorrect because measuring the effect of each feature as the weight of the feature multiplied by the feature value is not a valid way to explain the difference between the actual prediction and the average prediction for a given input. This method assumes that the model is linear and additive, which is not the case for an ensemble of trees and neural networks. Moreover, this method does not account for the interactions between features or the non-linearity of the model5.
References:
* Local surrogate models
* Shapley value
* Vertex Explainable AI overview
* Integrated gradients
* Feature importance
NEW QUESTION # 139
You recently developed a deep learning model using Keras, and now you are experimenting with different training strategies. First, you trained the model using a single GPU, but the training process was too slow.
Next, you distributed the training across 4 GPUs using tf.distribute.MirroredStrategy (with no other changes), but you did not observe a decrease in training time. What should you do?
- A. Create a custom training loop.
- B. Distribute the dataset with tf.distribute.Strategy.experimental_distribute_dataset
- C. Use a TPU with tf.distribute.TPUStrategy.
- D. Increase the batch size.
Answer: D
Explanation:
* Option A is incorrect because distributing the dataset with
tf.distribute.Strategy.experimental_distribute_dataset is not the most effective way to decrease the
* training time. This method allows you to distribute your dataset across multiple devices or machines, by creating a tf.data.Dataset instance that can be iterated over in parallel1. However, this option may not improve the training time significantly, as it does not change the amount of data or computation that each device or machine has to process. Moreover, this option may introduce additional overhead or complexity, as it requires you to handle the data sharding, replication, and synchronization across the devices or machines1.
* Option B is incorrect because creating a custom training loop is not the easiest way to decrease the training time. A custom training loop is a way to implement your own logic fortraining your model, by using low-level TensorFlow APIs, such as tf.GradientTape, tf.Variable, or tf.function2. A custom training loop may give you more flexibility and control over the training process, but it also requires more effort and expertise, as you have to write and debug the code for each step of the training loop, such as computing the gradients, applying the optimizer, or updating the metrics2. Moreover, a custom training loop may not improve the training time significantly, as it does not change the amount of data or computation that each device or machine has to process.
* Option C is incorrect because using a TPU with tf.distribute.TPUStrategy is not a valid way to decrease the training time. A TPU (Tensor Processing Unit) is a custom hardware acceleratordesigned for high-performance ML workloads3. A tf.distribute.TPUStrategy is a distribution strategy that allows you to distribute your training across multiple TPUs, by creating a tf.distribute.TPUStrategy instance that can be used with high-level TensorFlow APIs, such as Keras4. However, this option is not feasible, as Vertex AI Training does not support TPUs as accelerators for custom training jobs5. Moreover, this option may require significant code changes, as TPUs have different requirements and limitations than GPUs.
* Option D is correct because increasing the batch size is the best way to decrease the training time. The batch size is a hyperparameter that determines how many samples of data are processed in each iteration of the training loop. Increasing the batch size may reduce the training time, as it reduces the number of iterations needed to train the model, and it allows each device or machine to process more data in parallel. Increasing the batch size is also easy to implement, as it only requires changing a single hyperparameter. However, increasing the batch size may also affect the convergence and the accuracy of the model, so it is important to find the optimal batch size that balances the trade-off between the training time and the model performance.
References:
* tf.distribute.Strategy.experimental_distribute_dataset
* Custom training loop
* TPU overview
* tf.distribute.TPUStrategy
* Vertex AI Training accelerators
* [TPU programming model]
* [Batch size and learning rate]
* [Keras overview]
* [tf.distribute.MirroredStrategy]
* [Vertex AI Training overview]
* [TensorFlow overview]
NEW QUESTION # 140
You are training an object detection model using a Cloud TPU v2. Training time is taking longer than expected. Based on this simplified trace obtained with a Cloud TPU profile, what action should you take to decrease training time in a cost-efficient way?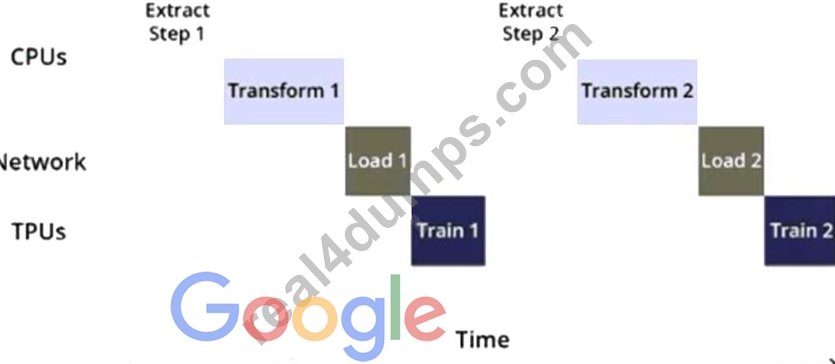
- A. Move from Cloud TPU v2 to Cloud TPU v3 and increase batch size.
- B. Rewrite your input function to resize and reshape the input images.
- C. Move from Cloud TPU v2 to 8 NVIDIA V100 GPUs and increase batch size.
- D. Rewrite your input function using parallel reads, parallel processing, and prefetch.
Answer: A
NEW QUESTION # 141
You are building a model to predict daily temperatures. You split the data randomly and then transformed the training and test datasets. Temperature data for model training is uploaded hourly. During testing, your model performed with 97% accuracy; however, after deploying to production, the model's accuracy dropped to 66%. How can you make your production model more accurate?
- A. Normalize the data for the training, and test datasets as two separate steps.
- B. Add more data to your test set to ensure that you have a fair distribution and sample for testing
- C. Apply data transformations before splitting, and cross-validate to make sure that the transformations are applied to both the training and test sets.
- D. Split the training and test data based on time rather than a random split to avoid leakage
Answer: B
NEW QUESTION # 142
You are building a MLOps platform to automate your company's ML experiments and model retraining. You need to organize the artifacts for dozens of pipelines How should you store the pipelines' artifacts'?
- A. Store parameters in Vertex ML Metadata and store the models source code and binaries in GitHub.
- B. Store parameters in Cloud SQL store the models' source code in GitHub, and store the models' binaries in Cloud Storage.
- C. Store parameters in Cloud SQL and store the models' source code and binaries in GitHub
- D. Store parameters in Vertex ML Metadata store the models' source code in GitHub and store the models' binaries in Cloud Storage.
Answer: D
NEW QUESTION # 143
You work for a company that is developing a new video streaming platform. You have been asked to create a recommendation system that will suggest the next video for a user to watch. After a review by an AI Ethics team, you are approved to start development. Each video asset in your company's catalog has useful metadata (e.g., content type, release date, country), but you do not have any historical user event dat a. How should you build the recommendation system for the first version of the product?
- A. Launch the product with machine learning. Use a publicly available dataset such as MovieLens to train a model using the Recommendations AI, and then apply this trained model to your data.
- B. Launch the product with machine learning. Generate embeddings for each video by training an autoencoder on the content metadata using TensorFlow. Cluster content based on the similarity of these embeddings, and then recommend videos from the same cluster.
- C. Launch the product without machine learning. Use simple heuristics based on content metadata to recommend similar videos to users, and start collecting user event data so you can develop a recommender model in the future.
- D. Launch the product without machine learning. Present videos to users alphabetically, and start collecting user event data so you can develop a recommender model in the future.
Answer: A
NEW QUESTION # 144
You manage a team of data scientists who use a cloud-based backend system to submit training jobs. This system has become very difficult to administer, and you want to use a managed service instead. The data scientists you work with use many different frameworks, including Keras, PyTorch, theano, scikit-learn, and custom libraries. What should you do?
- A. Configure Kubeflow to run on Google Kubernetes Engine and submit training jobs through TFJob.
- B. Use the Vertex AI Training to submit training jobs using any framework.
- C. Set up Slurm workload manager to receive jobs that can be scheduled to run on your cloud infrastructure.
- D. Create a library of VM images on Compute Engine, and publish these images on a centralized repository.
Answer: B
Explanation:
The best option for using a managed service to submit training jobs with different frameworks is to use Vertex AI Training. Vertex AI Training is a fully managed service that allows you to train custom models on Google Cloud using any framework, such as TensorFlow, PyTorch, scikit-learn, XGBoost, etc. You can also use custom containers to run your own libraries and dependencies. Vertex AI Training handles the infrastructure provisioning, scaling, and monitoring for you, so you can focus on your model development and optimization.
Vertex AI Training also integrates with other Vertex AI services, such as Vertex AI Pipelines, Vertex AI Experiments, and Vertex AI Prediction. The other options are not as suitable for using a managed service to submit training jobs with different frameworks, because:
* Configuring Kubeflow to run on Google Kubernetes Engine and submit training jobs through TFJob
* would require more infrastructure maintenance, as Kubeflow is not a fully managed service, and you would have to provision and manage your own Kubernetes cluster. This would also incur more costs, as you would have to pay for the cluster resources, regardless of the training job usage. TFJob is also mainly designed for TensorFlow models, and might not support other frameworks as well as Vertex AI Training.
* Creating a library of VM images on Compute Engine, and publishing these images on a centralized repository would require more development time and effort, as you would have to create and maintain different VM images for different frameworks and libraries. You would also have to manually configure and launch the VMs for each training job, and handle the scaling and monitoring yourself. This would not leverage the benefits of a managed service, such as Vertex AI Training.
* Setting up Slurm workload manager to receive jobs that can be scheduled to run on your cloud infrastructure would require more configuration and administration, as Slurm is not a native Google Cloud service, and you would have to install and manage it on your own VMs or clusters. Slurm is also a general-purpose workload manager, and might not have the same level of integration and optimization for ML frameworks and libraries as Vertex AI Training. References:
* Vertex AI Training | Google Cloud
* Kubeflow on Google Cloud | Google Cloud
* TFJob for training TensorFlow models with Kubernetes | Kubeflow
* Compute Engine | Google Cloud
* Slurm Workload Manager
NEW QUESTION # 145
You trained a text classification model. You have the following SignatureDefs: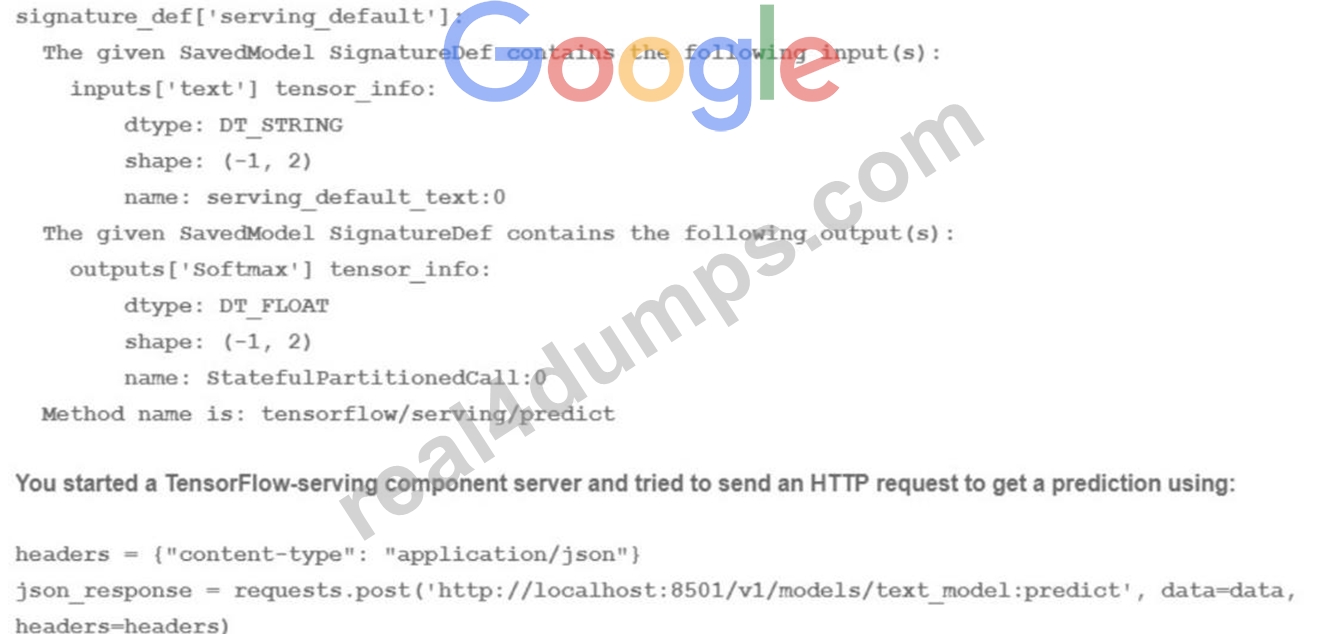
What is the correct way to write the predict request?
- A. data = json.dumps({"signature_name": "serving_default, "instances": [['a', 'b\ 'c'1, [d\ 'e\ T]]})
- B. data = json dumps({"signature_name": f,serving_default", "instances": [['a', 'b'], [c\ 'd'], ['e\ T]]})
- C. data = json dumps({"signature_name": "serving_default"! "instances": [['a', 'b', "c", 'd', 'e', 'f']]})
- D. data = json.dumps({"signature_name": "serving_default'\ "instances": [fab', 'be1, 'cd']]})
Answer: B
Explanation:
https://stackoverflow.com/questions/37956197/what-is-the-negative-index-in-shape-arrays-used-for-tensorflow
NEW QUESTION # 146
You deployed an ML model into production a year ago. Every month, you collect all raw requests that were sent to your model prediction service during the previous month. You send a subset of these requests to a human labeling service to evaluate your model'sperformance. After a year, you notice that your model's performance sometimes degrades significantly after a month, while other times it takes several months to notice any decrease in performance. The labeling service is costly, but you also need to avoid large performance degradations. You want to determine how often you should retrain your model to maintain a high level of performance while minimizing cost. What should you do?
- A. Run training-serving skew detection batch jobs every few days to compare the aggregate statistics of the features in the training dataset with recent serving data. If skew is detected, send the most recent serving data to the labeling service.
- B. Identify temporal patterns in your model's performance over the previous year. Based on these patterns, create a schedule for sending serving data to the labeling service for the next year.
- C. Train an anomaly detection model on the training dataset, and run all incoming requests through this model. If an anomaly is detected, send the most recent serving data to the labeling service.
- D. Compare the cost of the labeling service with the lost revenue due to model performance degradation over the past year. If the lost revenue is greater than the cost of the labeling service, increase the frequency of model retraining; otherwise, decrease the model retraining frequency.
Answer: A
Explanation:
The best option for determining how often to retrain your model to maintain a high level of performance while minimizing cost is to run training-serving skew detection batch jobs every few days. Training-serving skew refers to the discrepancy between the distributions of the features in the training dataset and the serving data. This can cause the model to perform poorly on the new data, as it is not representative of the data that the model was trained on. By running training-serving skew detection batch jobs, you can monitor the changes in the feature distributions over time, and identify when the skew becomes significant enough to affect the model performance. If skew is detected, you can send the most recent serving data to the labeling service, and use the labeled data to retrain your model. This option has the following benefits:
* It allows you to retrain your model only when necessary, based on the actual data changes, rather than on a fixed schedule or a heuristic. This can save you the cost of the labeling service and the retraining process, and also avoid overfitting or underfitting your model.
* It leverages the existing tools and frameworks for training-serving skew detection, such as TensorFlow Data Validation (TFDV) and Vertex Data Labeling. TFDV is a library that can compute and visualize descriptive statistics for your datasets, and compare the statistics across different datasets. Vertex Data Labeling is a service that can label your data with high quality and low latency, using either human labelers or automated labelers.
* It integrates well with the MLOps practices, such as continuous integration and continuous delivery (CI/CD), which can automate the workflow of running the skew detection jobs, sending the data to the labeling service, retraining the model, and deploying the new model version.
The other options are less optimal for the following reasons:
* Option A: Training an anomaly detection model on the training dataset, and running all incoming requests through this model, introduces additional complexity and overhead. This option requires
* building and maintaining a separate model for anomaly detection, which can be challenging and time-consuming. Moreover, this option requires running the anomaly detection model on every request, which can increase the latency and resource consumption of the prediction service. Additionally, this option may not capture the subtle changes in the feature distributions that can affect the model performance, as anomalies are usually defined as rare or extreme events.
* Option B: Identifying temporal patterns in your model's performance over the previous year, and creating a schedule for sending serving data to the labeling service for the next year, introduces additional assumptions and risks. This option requires analyzing the historical data and model performance, and finding the patterns that can explain the variations in the model performance over time. However, this can be difficult and unreliable, as the patterns may not be consistent or predictable, and may depend on various factors that are not captured by the data. Moreover, this option requires creating a schedule based on the past patterns, which may not reflect the future changes in the data or the environment. This can lead to either sending too much or too little data to the labeling service, resulting in either wasted cost or degraded performance.
* Option C: Comparing the cost of the labeling service with the lost revenue due to model performance degradation over the past year, and adjusting the frequency of model retraining accordingly, introduces additional challenges and trade-offs. This option requires estimating the cost of the labeling service and the lost revenue due to model performance degradation, which can be difficult and inaccurate, as they may depend on various factors that are not easily quantifiable or measurable. Moreover, this option requires finding the optimal balance between the cost and the performance, which can be subjective and variable, as different stakeholders may have different preferences and expectations. Furthermore, this option may not account for the potential impact of the model performance degradation on other aspects of the business, such as customer satisfaction, retention, or loyalty.
NEW QUESTION # 147
You are an ML engineer at a manufacturing company You are creating a classification model for a predictive maintenance use case You need to predict whether a crucial machine will fail in the next three days so that the repair crew has enough time to fix the machine before it breaks. Regular maintenance of the machine is relatively inexpensive, but a failure would be very costly You have trained several binary classifiers to predict whether the machine will fail. where a prediction of 1 means that the ML model predicts a failure.
You are now evaluating each model on an evaluation dataset. You want to choose a model that prioritizes detection while ensuring that more than 50% of the maintenance jobs triggered by your model address an imminent machine failure. Which model should you choose?
- A. The model with the highest area under the receiver operating characteristic curve (AUC ROC) and precision greater than 0 5
- B. The model with the highest recall where precision is greater than 0.5.
- C. The model with the highest precision where recall is greater than 0.5.
- D. The model with the lowest root mean squared error (RMSE) and recall greater than 0.5.
Answer: B
Explanation:
The best option for choosing a model that prioritizes detection while ensuring that more than 50% of the maintenance jobs triggered by the model address an imminent machine failure is to choose the model with the highest recall where precision is greater than 0.5. This option has the following advantages:
* It maximizes the recall, which is the proportion of actual failures that are correctly predicted by the model. Recall is also known as sensitivity or true positive rate (TPR), and it is calculated as:
mathrmRecall=fracmathrmTPmathrmTP+mathrmFN
where TP is the number of true positives (actual failures that are predicted as failures) and FN is the number of false negatives (actual failures that are predicted as non-failures). By maximizing the recall, the model can reduce the number of false negatives, which are the most costly and undesirable outcomes for the predictive maintenance use case, as they represent missed failures that can lead to machine breakdown and downtime.
* It constrains the precision, which is the proportion of predicted failures that are actual failures. Precision is also known as positive predictive value (PPV), and it is calculated as:
mathrmPrecision=fracmathrmTPmathrmTP+mathrmFP
where FP is the number of false positives (actual non-failures that are predicted as failures). By constraining the precision to be greater than 0.5, the model can ensure that more than 50% of the maintenance jobs triggered by the model address an imminent machine failure, which can avoid unnecessary or wasteful maintenance costs.
The other options are less optimal for the following reasons:
* Option A: Choosing the model with the highest area under the receiver operating characteristic curve (AUC ROC) and precision greater than 0.5 may not prioritize detection, as the AUC ROC does not directly measure the recall. The AUC ROC is a summary metric that evaluates the overall performance of a binary classifier across all possible thresholds. The ROC curve plots the TPR (recall) against the
* false positive rate (FPR), which is the proportion of actual non-failures that are incorrectly predicted by the model. The AUC ROC is the area under the ROC curve, and it ranges from 0 to 1, where 1 represents a perfect classifier. However, choosing the model with the highest AUC ROC may not maximize the recall, as the AUC ROC is influenced by both the TPR and the FPR, and it does not account for the precision or the specificity (the proportion of actual non-failures that are correctly predicted by the model).
* Option B: Choosing the model with the lowest root mean squared error (RMSE) and recall greater than
0.5 may not prioritize detection, as the RMSE is not a suitable metric for binary classification. The RMSE is a regression metric that measures the average magnitude of the error between the predicted and the actual values. The RMSE is calculated as:
mathrmRMSE=sqrtfrac1nsumi=1n(yihatyi)2
where yi is the actual value, hatyi is the predicted value, and n is the number of observations. However, choosing the model with the lowest RMSE may not optimize the detection of failures, as the RMSE is sensitive to outliers and does not account for the class imbalance or the cost of misclassification.
* Option D: Choosing the model with the highest precision where recall is greater than 0.5 may not prioritize detection, as the precision may not be the most important metric for the predictive maintenance use case. The precision measures the accuracy of the positive predictions, but it does not reflect the sensitivity or the coverage of the model. By choosing the model with the highest precision, the model may sacrifice the recall, which is the proportion of actual failures that are correctly predicted by the model. This may increase the number of false negatives, which are the most costly and undesirable outcomes for the predictive maintenance use case, as they represent missed failures that can lead to machine breakdown and downtime.
References:
* Evaluation Metrics (Classifiers) - Stanford University
* Evaluation of binary classifiers - Wikipedia
* Predictive Maintenance: The greatest benefits and smart use cases
NEW QUESTION # 148
You are designing an architecture with a serverless ML system to enrich customer support tickets with informative metadata before they are routed to a support agent. You need a set of models to predict ticket priority, predict ticket resolution time, and perform sentiment analysis to help agents make strategic decisions when they process support requests. Tickets are not expected to have any domain-specific terms or jargon.
The proposed architecture has the following flow:
Which endpoints should the Enrichment Cloud Functions call?
- A. 1 = cloud Natural Language API, 2 = Al Platform, 3 = Cloud Vision API
- B. 1 = Al Platform, 2 = Al Platform, 3 = AutoML Vision
- C. 1 = Al Platform, 2 = Al Platform, 3 = Cloud Natural Language API
- D. 1 = Al Platform, 2 = Al Platform, 3 = AutoML Natural Language
Answer: C
Explanation:
https://cloud.google.com/architecture/architecture-of-a-serverless-ml-model#architecture The architecture has the following flow:
A user writes a ticket to Firebase, which triggers a Cloud Function.
-The Cloud Function calls 3 different endpoints to enrich the ticket:
-An AI Platform endpoint, where the function can predict the priority.
-An AI Platform endpoint, where the function can predict the resolution time.
-The Natural Language API to do sentiment analysis and word salience.
-For each reply, the Cloud Function updates the Firebase real-time database.
-The Cloud Function then creates a ticket into the helpdesk platform using the RESTful API.
NEW QUESTION # 149
You work for an online publisher that delivers news articles to over 50 million readers. You have built an AI model that recommends content for the company's weekly newsletter. A recommendation is considered successful if the article is opened within two days of the newsletter's published date and the user remains on the page for at least one minute.
All the information needed to compute the success metric is available in BigQuery and is updated hourly. The model is trained on eight weeks of data, on average its performance degrades below the acceptable baseline after five weeks, and training time is 12 hours. You want to ensure that the model's performance is above the acceptable baseline while minimizing cost. How should you monitor the model to determine when retraining is necessary?
- A. Schedule a weekly query in BigQuery to compute the success metric.
- B. Schedule a cron job in Cloud Tasks to retrain the model every week before the newsletter is created.
- C. Use Vertex AI Model Monitoring to detect skew of the input features with a sample rate of 100% and a monitoring frequency of two days.
- D. Schedule a daily Dataflow job in Cloud Composer to compute the success metric.
Answer: A
Explanation:
The best option for monitoring the model to determine when retraining is necessary is to schedule a weekly query in BigQuery to compute the success metric. This option has the following advantages:
* It allows the model performance to be evaluated regularly, based on the actual outcome of the recommendations. By computing the success metric, which is the percentage of articles that are opened within two days and read for at least one minute, you can measure how well the model is achieving its objective and compare it with the acceptable baseline.
* It leverages the scalability and efficiency of BigQuery, which is a serverless, fully managed, and highly scalable data warehouse that can run complex queries over petabytes of data in seconds. By using BigQuery, you can access and analyze all the information needed to compute the success metric, such as the newsletter publication date, the article opening date, and the user reading time, without worrying about the infrastructure or the cost.
* It simplifies the model monitoring and retraining workflow, as the weekly query can be scheduled and executed automatically using BigQuery's built-in scheduling feature. You can also set up alerts or notifications to inform you when the success metric falls below the acceptable baseline, and trigger the model retraining process accordingly.
The other options are less optimal for the following reasons:
* Option A: Using Vertex AI Model Monitoring to detect skew of the input features with a sample rate of
100% and a monitoring frequency of two days introduces additional complexity and overhead. This option requires setting up and managing a Vertex AI Model Monitoring service, which is a managed service that provides various tools and features for machine learning, such as training, tuning, serving, and monitoring. However, using Vertex AI Model Monitoring to detect skew of the input features may not reflect the actual performance of the model, as skew is the discrepancy between the distributions of the features in the training dataset and the serving data, which may not affect the outcome of the recommendations. Moreover, using a sample rate of 100% and a monitoring frequency of two days may incur unnecessary cost and latency, as it requires analyzing all the input features every two days, which may not be needed for the model monitoring.
* Option B: Scheduling a cron job in Cloud Tasks to retrain the model every week before the newsletter is created introduces additional cost and risk. This option requires creating and running a cron job in Cloud Tasks, which is a fully managed service that allows you to schedule and execute tasks that are invoked by HTTP requests. However, using Cloud Tasks to retrain the model every week may not be optimal, as it may retrain the model more often than necessary, wasting compute resources and cost. Moreover, using Cloud Tasks to retrain the model before the newsletter is created may introduce risk, as it may deploy a new model version that has not been tested or validated, potentially affecting the quality of the recommendations.
* Option D: Scheduling a daily Dataflow job in Cloud Composer to compute the success metric introduces additional complexity and cost. This option requires creating and running a Dataflow job in Cloud Composer, which is a fully managed service that runs Apache Airflow pipelines for workflow orchestration. Dataflow is a fully managed service that runs Apache Beam pipelines for data processing and transformation. However, using Dataflow and Cloud Composer to compute the success metric may not be necessary, as it may add more steps and overhead to the model monitoring process. Moreover,
* using Dataflow and Cloud Composer to compute the success metric daily may not be optimal, as it may compute the success metric more often than needed, consuming more compute resources and cost.
References:
* [BigQuery documentation]
* [Vertex AI Model Monitoring documentation]
* [Cloud Tasks documentation]
* [Cloud Composer documentation]
* [Dataflow documentation]
NEW QUESTION # 150
You recently deployed a scikit-learn model to a Vertex Al endpoint You are now testing the model on live production traffic While monitoring the endpoint. you discover twice as many requests per hour than expected throughout the day You want the endpoint to efficiently scale when the demand increases in the future to prevent users from experiencing high latency What should you do?
- A. Deploy two models to the same endpoint and distribute requests among them evenly.
- B. Configure an appropriate minReplicaCount value based on expected baseline traffic.
- C. Change the model's machine type to one that utilizes GPUs.
- D. Set the target utilization percentage in the autcscalir.gMetricspecs configuration to a higher value
Answer: B
Explanation:
The best option for scaling a Vertex AI endpoint efficiently when the demand increases in the future, using a scikit-learn model that is deployed to a Vertex AI endpoint and tested on live production traffic, is to configure an appropriate minReplicaCount value based on expected baseline traffic. This option allows you to leverage the power and simplicity of Vertex AI to automatically scale your endpoint resources according to the traffic patterns. Vertex AI is a unified platform for building and deploying machine learning solutions on Google Cloud. Vertex AI can deploy a trained model to an online prediction endpoint, which can provide low-latency predictions for individual instances. Vertex AI can also provide various tools and services for data analysis, model development, model deployment, model monitoring, and model governance. A minReplicaCount value is a parameter that specifies the minimum number of replicas that the endpoint must always have, regardless of the load. A minReplicaCount value can help you ensure that the endpoint has enough resources to handle the expected baseline traffic, and avoid high latency or errors. By configuring an appropriate minReplicaCount value based on expected baseline traffic, you can scale your endpoint efficiently when the demand increases in the future. You can set the minReplicaCount value when you deploy the model to the endpoint, or update it later. Vertex AI will automatically scale up or down the number of replicas within the range of the minReplicaCount and maxReplicaCount values, based on the target utilization percentage and the autoscaling metric1.
The other options are not as good as option B, for the following reasons:
* Option A: Deploying two models to the same endpoint and distributing requests among them evenly would not allow you to scale your endpoint efficiently when the demand increases in the future, and could increase the complexity and cost of the deployment process. A model is a resource that represents a machine learning model that you can use for prediction. A model can have one or more versions, which are different implementations of the same model. A model version can help you experiment and iterate on your model, and improve the model performance and accuracy. An endpoint is a resource that provides the service endpoint (URL) you use to request the prediction. An endpoint can have one or more deployed models, which are instances of model versions that are associated with physical resources. A deployed model can help you serve online predictions with low latency, and scale up or down based on the traffic. By deploying two models to the same endpoint and distributing requests among them evenly, you can create a load balancing mechanism that can distribute the traffic across the models, and reduce the load on each model. However, deploying two models to the same endpoint and distributing requests among them evenly would not allow you to scale your endpoint efficiently when the demand increases in the future, and could increase the complexity and cost of the deployment process. You would need to write code, create and configure the two models, deploy the models to the same endpoint, and distribute the requests among them evenly. Moreover, this option would not use the autoscaling feature of Vertex AI, which can automatically adjust the number of replicas based on the traffic patterns, and provide various benefits, such as optimal resource utilization, cost savings, and performance improvement2.
* Option C: Setting the target utilization percentage in the autoscalingMetricSpecs configuration to a higher value would not allow you to scale your endpoint efficiently when the demand increases in the future, and could cause errors or poor performance. A target utilization percentage is a parameter that specifies the desired utilization level of each replica. A target utilization percentage can affect the speed and accuracy of the autoscaling process. A higher target utilization percentage can help you reduce the number of replicas, but it can also cause high latency, low throughput, or resource exhaustion. By setting the target utilization percentage in the autoscalingMetricSpecs configuration to a higher value, you can increase the utilization level of each replica, and save some resources. However, setting the target utilization percentage in the autoscalingMetricSpecs configuration to a higher value would not allow you to scale your endpoint efficiently when the demand increases in the future, and could cause errors or poor performance. You would need to write code, create and configure the autoscalingMetricSpecs, and set the target utilization percentage to a higher value. Moreover, this option would not ensure that the endpoint has enough resources to handle the expected baseline traffic, which could cause high latency or errors1.
* Option D: Changing the model's machine type to one that utilizes GPUs would not allow you to scale your endpoint efficiently when the demand increases in the future, and could increase the complexity and cost of the deployment process. A machine type is a parameter that specifies the type of virtual machine that the prediction service uses for the deployed model. A machine type can affect the speed and accuracy of the prediction process. A machine type that utilizes GPUs can help you accelerate the computation and processing of the prediction, and handle more prediction requests at the same time. By
* changing the model's machine type to one that utilizes GPUs, you can improve the prediction performance and efficiency of your model. However, changing the model's machine type to one that utilizes GPUs would not allow you to scale your endpoint efficiently when the demand increases in the future, and could increase the complexity and cost of the deployment process. You would need to write code, create and configure the model, deploy the model to the endpoint, and change the machine type to one that utilizes GPUs. Moreover, this option would not use the autoscaling feature of Vertex AI, which can automatically adjust the number of replicas based on the traffic patterns, and provide various benefits, such as optimal resource utilization, cost savings, and performance improvement2.
References:
* Configure compute resources for prediction | Vertex AI | Google Cloud
* Deploy a model to an endpoint | Vertex AI | Google Cloud
NEW QUESTION # 151
You are responsible for building a unified analytics environment across a variety of on-premises data marts.
Your company is experiencing data quality and security challenges when integrating data across the servers, caused by the use of a wide rangeof disconnected tools and temporary solutions. You need a fully managed, cloud-native data integration service that will lower the total cost of work and reduce repetitive work. Some members on your team prefer a codeless interface for building Extract, Transform, Load (ETL) process.
Which service should you use?
- A. Dataprep
- B. Apache Flink
- C. Dataflow
- D. Cloud Data Fusion
Answer: D
Explanation:
Cloud Data Fusion is a fully managed, cloud-native data integration service that helps users efficiently build and manage ETL/ELT data pipelines. It provides a graphical interface to increase time efficiency and reduce complexity, and allows users to easily create and explore data pipelines using a code-free, point and click visual interface. Cloud Data Fusion also supports a broad range of data sources and formats, including on-premises data marts, and ensures data quality and security by using built-in transformation capabilities and Cloud Data Loss Prevention. Cloud Data Fusion lowers the total cost of ownership by handling performance, scalability, availability, security, and compliance needs automatically. References:
* Cloud Data Fusion documentation
* Cloud Data Fusion overview
NEW QUESTION # 152
You work on a growing team of more than 50 data scientists who all use AI Platform. You are designing a strategy to organize your jobs, models, and versions in a clean and scalable way. Which strategy should you choose?
- A. Use labels to organize resources into descriptive categories. Apply a label to each created resource so that users can filter the results by label when viewing or monitoring the resources.
- B. Set up a BigQuery sink for Cloud Logging logs that is appropriately filtered to capture information about AI Platform resource usage. In BigQuery, create a SQL view that maps users to the resources they are using
- C. Set up restrictive IAM permissions on the AI Platform notebooks so that only a single user or group can access a given instance.
- D. Separate each data scientist's work into a different project to ensure that the jobs, models, and versions created by each data scientist are accessible only to that user.
Answer: C
NEW QUESTION # 153
You are training a deep learning model for semantic image segmentation with reduced training time. While using a Deep Learning VM Image, you receive the following error: The resource
'projects/deeplearning-platforn/zones/europe-west4-c/acceleratorTypes/nvidia-tesla-k80' was not found. What should you do?
- A. Ensure that the required GPU is available in the selected region.
- B. Ensure that you have GPU quota in the selected region.
- C. Ensure that you have preemptible GPU quota in the selected region.
- D. Ensure that the selected GPU has enough GPU memory for the workload.
Answer: A
Explanation:
The error message indicates that the selected GPU type (nvidia-tesla-k80) is not available in the selected region (europe-west4-c). This can happen when the GPU type is not supported in the region, or when the GPU quota is exhausted in the region. To avoid this error, you should ensure that the required GPU is available in the selected region before creating a Deep Learning VM Image. You can use the following steps to check the GPU availability and quota:
* To check the GPU availability, you can use the gcloud compute accelerator-types list command with the --filter flag to specify the GPU type and the region. For example, to check the availability of nvidia-tesla-k80 in europe-west4-c, you can run:
gcloud compute accelerator-types list --filter="name=nvidia-tesla-k80 AND zone:europe-west4-c"
* If the command returns an empty result, it means that the GPU type is not supported in the region. You can either choose a different GPU type or a different region that supports the GPU type. You can use the same command without the --filter flag to list all the available GPU types and regions. For example, to list all the available GPU types in europe-west4-c, you can run:
gcloud compute accelerator-types list --filter="zone:europe-west4-c"
* To check the GPU quota, you can use the gcloud compute regions describe command with the --format flag to specify the region and the quota metric. For example, to check the quota for nvidia-tesla-k80 in europe-west4-c, you can run:
gcloud compute regions describe europe-west4-c --format="value(quotas.NVIDIA_K80_GPUS)"
* If the command returns a value of 0, it means that the GPU quota is exhausted in the region. You can either request more quota from Google Cloud or choose a different region that has enough quota for the GPU type.
References:
* Troubleshooting | Deep Learning VM Images | Google Cloud
* Checking GPU availability
* Checking GPU quota
NEW QUESTION # 154
You are working on a binary classification ML algorithm that detects whether an image of a classified scanned document contains a company's logo. In the dataset, 96% of examples don't have the logo, so the dataset is very skewed. Which metrics would give you the most confidence in your model?
- A. F1 score
- B. F-score where recall is weighed more than precision
- C. RMSE
- D. F-score where precision is weighed more than recall
Answer: B
Explanation:
* Option A is correct because using F-score where recall is weighed more than precision is a suitable metric for binary classification with imbalanced data. F-score is a harmonic mean of precision and recall, which are two metrics that measure the accuracy and completeness of the positive class1. Precision is the fraction of true positives among all predicted positives, while recall is the fraction of true positives among all actual positives1. When the data is imbalanced, the positive class is the minority class, which is usually the class of interest. For example, in this case, the positive class is the images that contain the company's logo, which are rare but important to detect. By weighing recall more than precision, we can emphasize the importance of finding all the positive examples, even if some false positives are included2.
* Option B is incorrect because using RMSE (root mean squared error) is not a valid metric for binary classification with imbalanced data. RMSE is a metric that measures the average magnitude of the errors between the predicted and actual values3. RMSE is suitable for regression problems, where the target variable is continuous, not for classification problems, where the target variable is discrete4.
* Option C is incorrect because using F1 score is not the best metric for binary classification with imbalanced data. F1 score is a special case of F-score where precision and recall are equally weighted1. F1 score is suitable for balanced data, where the positive and negative classes are equally important and frequent5. However, for imbalanced data, the positive class is more important and less frequent than the negative class, so F1 score may not reflect the performance of the model well2.
* Option D is incorrect because using F-score where precision is weighed more than recall is not a good metric for binary classification with imbalanced data. By weighing precision more than recall, we can
* emphasize the importance of minimizing the false positives, even if some true positives are missed2. However, for imbalanced data, the true positives are more important and less frequent than the false positives, so this metric may not reflect the performance of the model well2.
References:
* Precision, recall, and F-measure
* F-score for imbalanced data
* RMSE
* Regression vs classification
* F1 score
* [Imbalanced classification]
* [Binary classification]
NEW QUESTION # 155
......
The Google Professional Machine Learning Engineer certification exam is intended for machine learning engineers, data scientists, and software engineers who are interested in designing and building scalable and efficient machine learning models on the Google Cloud Platform. Candidates who pass the certification exam will be able to demonstrate their proficiency in machine learning and will be recognized as a Google Professional Machine Learning Engineer.
Pass Your Google Exam with Professional-Machine-Learning-Engineer Exam Dumps: https://prep4sure.real4dumps.com/Professional-Machine-Learning-Engineer-prep4sure-exam.html